
The GIL Was Your Lock

If you’ve ever looked at your threaded Python code and thought:
“It’s fine. The GIL will keep me safe.”
…this one’s for you.
This post is a story about two bugs that were always there, but the GIL made them look “correct” — until free‑threading showed up and ripped the mask off.
Terms (one minute)
Race condition: the outcome depends on timing/interleaving; you can have one even if no single machine word is being “torn.”
Data race (C/C++ sense): two threads access the same memory concurrently, at least one is a write, and there is no synchronization. In C/C++, this is undefined behavior.
In this post: Act 1 is a Python‑level invariant getting observed mid‑update; Act 3 is a deliberate C‑level data race (and the symptom we’ll measure is tearing).
What changes in free‑threading (30 seconds)
Free‑threaded CPython doesn’t mean “no locks”. It removes the single global lock (the GIL) and replaces it with finer‑grained synchronization to keep the interpreter and object model memory‑safe. That’s about CPython’s correctness — not your program’s: multi‑step updates to shared state still aren’t atomic, and without explicit coordination you can observe mid‑update snapshots.
Act 1: I went hunting for the most obvious torn invariant possible
I wanted a concurrency bug that’s basically a meme:
one thread (”mover”) updates two fields in a specific pattern
another thread (”checker”) tries to catch the object in a half-updated state
no locks, no atomics, no mercy
Here’s the idea (simplified):
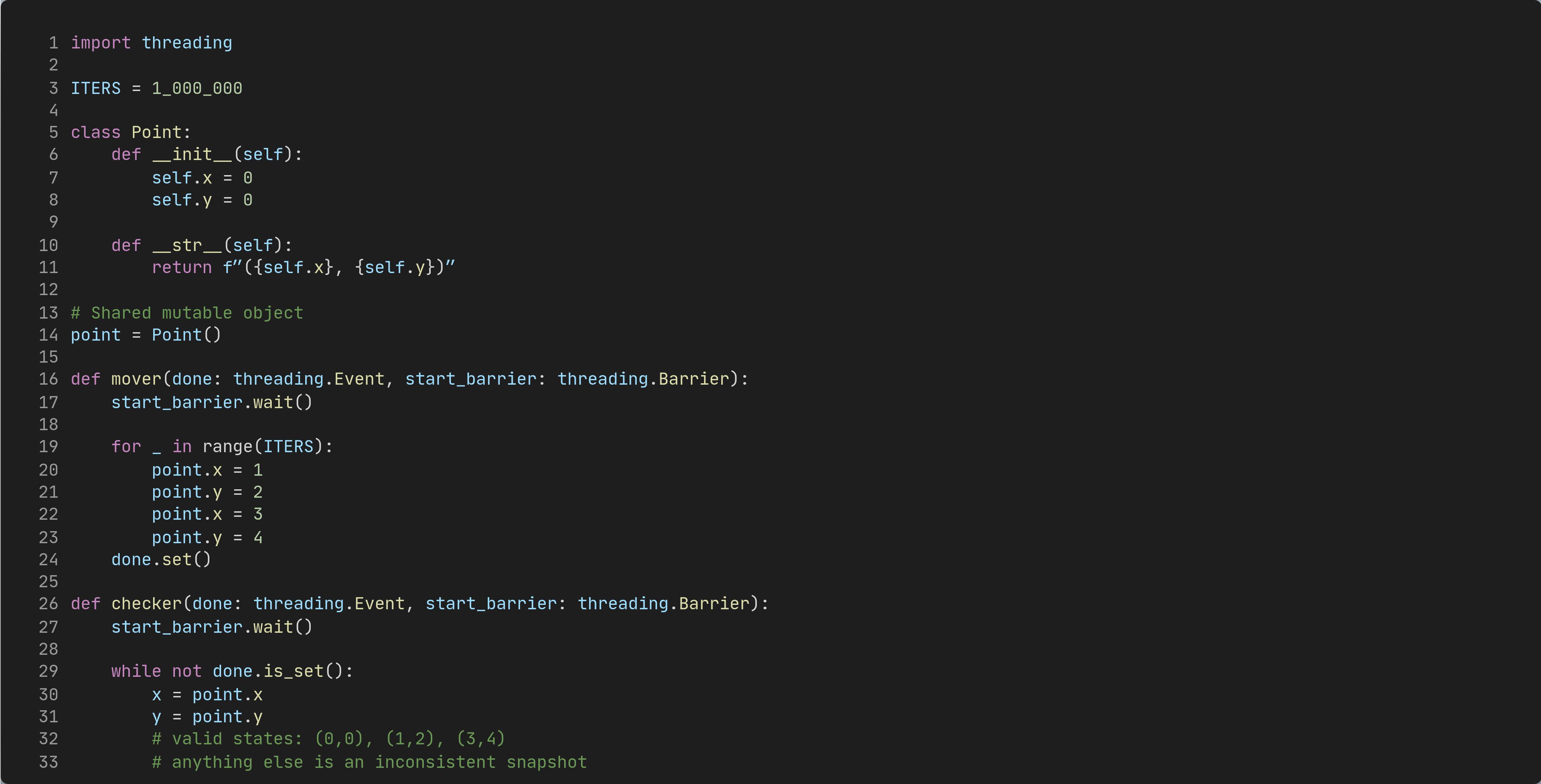
This should be racy. We’re updating a two‑field invariant with multiple steps. A reader can observe a “torn” pair like (1,4) or (3,2).
And then I ran it.
First run: the GIL build looks innocent
uv run --python 3.14+gil data_races/classic_data_race.py
=== environment ===
Python (cpython): 3.14.2 (main, Dec 9 2025, 19:03:28) [Clang 21.1.4 ]
OS: Linux-6.17.0-8-generic-x86_64-with-glibc2.42, arch x86_64
Config: ITERS=1000000, WIDEN=False, WORK_ITERS=10
Current thread switch interval: 0.005, setting it to 0.0001
===================
Inconsistent states observed: 0Zero. Nada. “Looks fine.”
Second run: free‑threading screams instantly
uv run --python 3.14t data_races/classic_data_race.py
=== environment ===
Python (cpython): 3.14.2 free-threading build (main, Dec 9 2025, 19:03:17) [Clang 21.1.4 ]
OS: Linux-6.17.0-8-generic-x86_64-with-glibc2.42, arch x86_64
Config: ITERS=1000000, WIDEN=False, WORK_ITERS=10
Current thread switch interval: 0.005, setting it to 0.0001
===================
Inconsistent states observed: 346925Hundreds of thousands of “WTFs.” So… does free‑threading “break” Python?
No.
It breaks my illusions.
Act 2: The GIL build was racy too — it just hid it well
Why did the GIL build show 0?
Because the “bad window” was tiny.
In the classic GIL build, only one thread runs Python bytecode at a time. CPython periodically hands off the GIL (roughly guided by sys.setswitchinterval()). Additionally, some C code (in the stdlib and extensions) explicitly releases the GIL (e.g. via Py_BEGIN_ALLOW_THREADS) around blocking I/O or long‑running work. The exact handoff points are implementation details — but the key is that CPython can switch between your logically related steps.
Your critical window is:
after
x = 1but beforey = 2after
x = 3but beforey = 4
Those gaps are usually microseconds or less. The scheduler just doesn’t land there often.
So I did the practical thing: I widened the window.
The “make it obvious” knob
I widened the window by doing a tiny bit of CPU‑only work between the stores.
In the script it’s controlled by environment variables:
WIDEN=1to enable wideningWORK_ITERS=...to tune how much work happensSWITCH_INTERVAL=...andITERS=...if you want to tune scheduling pressure
Conceptually it’s just:
point.x = 1
if WIDEN:
tiny_cpu_work(WORK_ITERS)
point.y = 2(Full version in classic_data_race.py; PRINT_BYTECODE=1 dumps the disassembly.)
Now even the GIL build can’t hide.
GIL build, patched: the bug finally shows its face
WIDEN=1 uv run --python 3.14+gil data_races/classic_data_race.py
=== environment ===
Python (cpython): 3.14.2 (main, Dec 9 2025, 19:03:28) [Clang 21.1.4 ]
OS: Linux-6.17.0-8-generic-x86_64-with-glibc2.42, arch x86_64
Config: ITERS=1000000, WIDEN=True, WORK_ITERS=10
Current thread switch interval: 0.005, setting it to 0.0001
===================
Inconsistent states observed: 7745270Seven million inconsistent snapshots.
Same interpreter family. Same “GIL safety.” Different visibility.
Intermission: “But I thought bytecode is atomic?”
Here’s the nuance people half‑remember:
In the classic build, CPython executes Python bytecode while holding the GIL, which makes individual interpreter steps “atomic‑ish” with respect to other Python threads.
But the invariant spans multiple steps, and steps can include function calls (which may run arbitrary Python/C code). That’s the whole problem.
My mover isn’t “one action.” It’s a sequence of actions:
(This is schematic — real dis output is noisier, especially on 3.11+ — but the important part is that the stores/calls are distinct steps.)
STORE_ATTR x
CALL tiny_cpu_work
STORE_ATTR y
CALL tiny_cpu_work
STORE_ATTR x
CALL tiny_cpu_work
STORE_ATTR y
CALL tiny_cpu_work
And CPython is allowed to switch threads between those steps.
That’s why the reader can see “torn” pairs.
Atomic steps do not imply an atomic story.
Act 3: Okay, let’s stop playing in Python. Let’s race memcpy().
At this point I wanted something more savage:
not Python attributes
not “did the scheduler feel generous”
something that screams “this is a real data race”
So I wrote a ctypes demo:
load
libccall
memcpy()in a tight looptwo writers copy different patterns into the same shared buffer
one reader snapshots the buffer and checks if it’s exactly A or exactly B
anything else is tearing (a mixed snapshot)
The code shape (key bits)
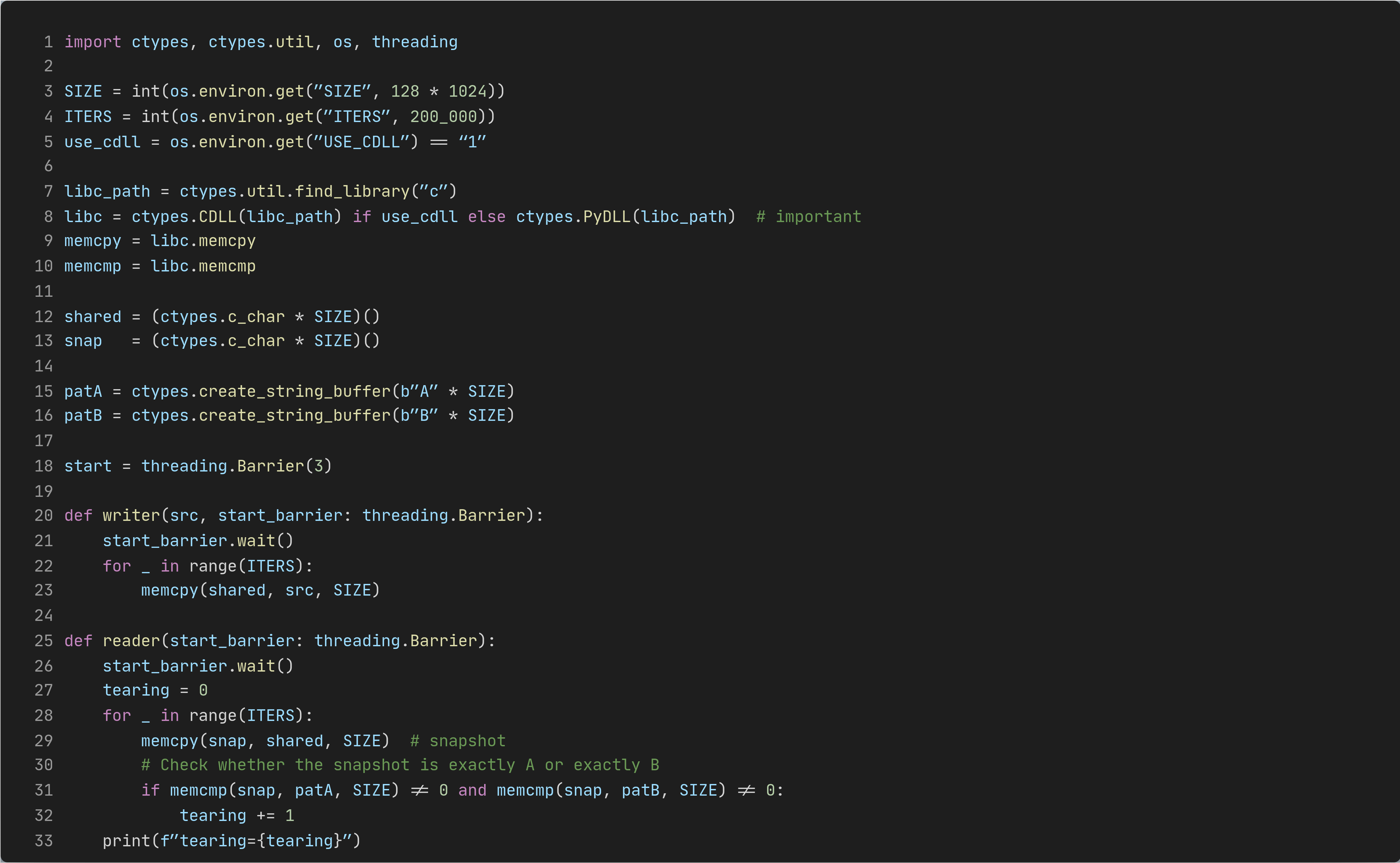
You can feel the bug from across the room:
two concurrent writes to the same memory
a concurrent read of that same memory
zero synchronization
That’s not “a race condition” in the casual sense. That’s a data race on raw bytes.
At the C level this is undefined behavior: tearing is a common symptom, but crashes, hangs, or “looks fine on my machine” are all valid outcomes too.
The output (same script, two builds)
uv run --python 3.14+gil data_races/ctypes_pydll_tearing_demo.py
=== environment ===
Python (cpython): 3.14.2 (main, Dec 9 2025, 19:03:28) [Clang 21.1.4 ]
OS: Linux-6.17.0-8-generic-x86_64-with-glibc2.42, arch x86_64
===================
libc: libc.so.6 via PyDLL
Config: SIZE=131072 bytes, ITERS=200000, USE_CDLL=False
tearing=0uv run --python 3.14t data_races/ctypes_pydll_tearing_demo.py
=== environment ===
Python (cpython): 3.14.2 free-threading build (main, Dec 9 2025, 19:03:17) [Clang 21.1.4 ]
OS: Linux-6.17.0-8-generic-x86_64-with-glibc2.42, arch x86_64
===================
libc: libc.so.6 via PyDLL
Config: SIZE=131072 bytes, ITERS=200000, USE_CDLL=False
tearing=175351So what the hell happened?
Act 4: PyDLL didn’t “break” — it lost its superpower
The critical line is:
libc = ctypes.PyDLL(libc_path)ctypes.PyDLL is special in classic CPython:
normal
ctypes.CDLLreleases the GIL around foreign function callsctypes.PyDLLdoes not release the GIL during the call
In GIL‑land, that turns every memcpy() call into a tiny “only one thread at a time” section.
Meaning:
writer A is copying → writer B cannot run Python code concurrently
reader snapshots → writers aren’t copying at the same time
So your program looks “safe” not because memcpy is atomic (it absolutely is not), but because the GIL accidentally serializes the calls.
That’s the second punchline:
You weren’t writing a lock‑free program. You were outsourcing synchronization to the GIL.
If you want to see tearing on a classic GIL build too, swap PyDLL → CDLL (or run my script with USE_CDLL=1). ctypes.CDLL releases the GIL, so the memcpy() calls can overlap even on +gil.
Now enter free‑threading:
there’s no global GIL acting as a single giant mutex
threads can run in parallel
your
memcpy()calls overlap in time on different cores
And memcpy() happily copies in chunks. It does not care about your “whole buffer should be consistent” dreams.
So the reader sees mixed snapshots like:
AAAAAA...AAA BBBBBB...BBB AAAAA... (torn buffer)
Boom: tearing=175351.
Free‑threading didn’t “break ctypes.” It removed your accidental global mutex.
Fixes: boring, fast, and “I feel smug now”
If you want consistent snapshots, you need to synchronize publication of shared state.
Fix #1 (boring): lock it
Wrap all touching of shared state with one threading.Lock().
simplest
easiest to explain
lowest risk
may be slower, but usually “fast enough” unless you’re doing something insane (like this demo 😄)
Fix #2 (fast + clean): publish snapshots, don’t mutate invariants in‑place
For the Point(x, y) case:
don’t update two fields and hope readers catch both
publish a single immutable snapshot, e.g. one attribute holding a tuple
reader grabs one object reference → consistent view
Example:
class Point:
def __init__(self):
self.xy = (0, 0)
# mover thread
point.xy = (1, 2) # publish new snapshot
point.xy = (3, 4)
# reader thread
x, y = point.xy # one read -> no torn pairOne read of point.xy returns a reference to a single tuple object. Because the tuple itself is immutable, you see either the old pair or the new pair, never a mix.
Note that this ensures consistency (no tearing), but not necessarily visibility (the reader might see a stale value for a few cycles) or coordination. If you need to ensure the reader sees the latest value immediately, you still need a lock or other synchronization.
Fix #3 (sexy): double‑buffer and swap
For the memcpy() case:
writers write into their own private buffers
publish by swapping an index / pointer (atomic + with proper ordering)
reader always copies from the published buffer
In pure Python you typically still publish that index/pointer with a Lock/Condition (or a higher‑level primitive). Truly lock‑free publication usually means atomics in C.
What to remember
The GIL can make broken code look correct.
“Atomic bytecode” is not a magical shield; it just means one interpreter step runs at a time.
Multi‑step invariants need real synchronization (locks, snapshots, publish patterns).
Free‑threading didn’t break your program. It stopped hiding the parts that were already wrong.
Repro notes
The absolute counts depend heavily on CPU count, OS scheduling, and tuning (
SIZE,ITERS, andsys.setswitchinterval()); treat them as “yes/no” demonstrations.For
classic_data_race.py,WIDEN=1widens the window andWORK_ITERS=...tunes it;SWITCH_INTERVAL=...andITERS=...let you adjust scheduling pressure.The
ctypesdemo assumes a POSIX-ishlibc; on a GIL build,USE_CDLL=1usually makes tearing show up immediately.SIZE=...andITERS=...tune the workload, and aBarrierstarts the threads together for repeatability.
References
(And yes: the ctypes docs explain the CDLL/PyDLL GIL behavior — it’s not folklore.)
Interesting post! Thank you!
Do I correctly understand that types are atomic itself?