
Stop Allocating Per Label: A Data‑Driven Rust SymbolTable for OTLP/TSDB

When you ingest OTLP metrics at scale, you quickly learn that you’re not “storing time series data” — you’re mostly storing strings: metric names and label keys/values.
In Chronoxide (OTLP-native TSDB prototype), every incoming datapoint touches multiple label pairs, and every label pair touches two strings (key + value). That makes the SymbolTable (string interner) part of the ingestion hot path and a major contributor to memory footprint.
This post analyzes why my initial ArcSymbolTable implementation failed under a production workload of 11 million OTLP messages, and how replacing it with a custom ArenaSymbolTable reduced memory overhead and allocation counts by orders of magnitude. I also evaluated two Small-String Optimization (SSO) crates: german-str and smol_str.
TL;DR
ArcSymbolTable is simple but does ~1 heap allocation per unique symbol; on 100,513 unique strings: 100,530
alloc_callsandintern/unique8.89ms.ArenaSymbolTablePacked stores bytes in a single grow-only
Vec<u8>and keeps(offset,len)per symbol; on the same dataset: 18alloc_calls,intern/unique3.85ms, and 0.14% internal fragmentation.SmolStrSymbolTable is the best off-the-shelf SSO option I tried, but it still does 25,873 allocations and uses more memory than arena.
GermanSymbolTable spills often for this workload shape (12B inline cap vs ~13B typical strings), leading to 69,069 allocations and 6.73% internal fragmentation.
LassoSymbolTable (via lasso) keeps allocations low (20
alloc_calls), butintern/uniqueis slower at 6.43ms; for memory, rely on TrackingAllocator output (estimates are disabled).
What is a SymbolTable?
A SymbolTable maps strings to small integer IDs and back:
intern("service.name") -> SymbolId(123)resolve(SymbolId(123)) -> "service.name"lookup("service.name") -> Option<SymbolId>
Everything else (label sets, postings, dictionaries, etc.) can store SymbolId instead of storing/copying strings repeatedly.
In Chronoxide, SymbolId is a dense u32, and SymbolTable is a trait:
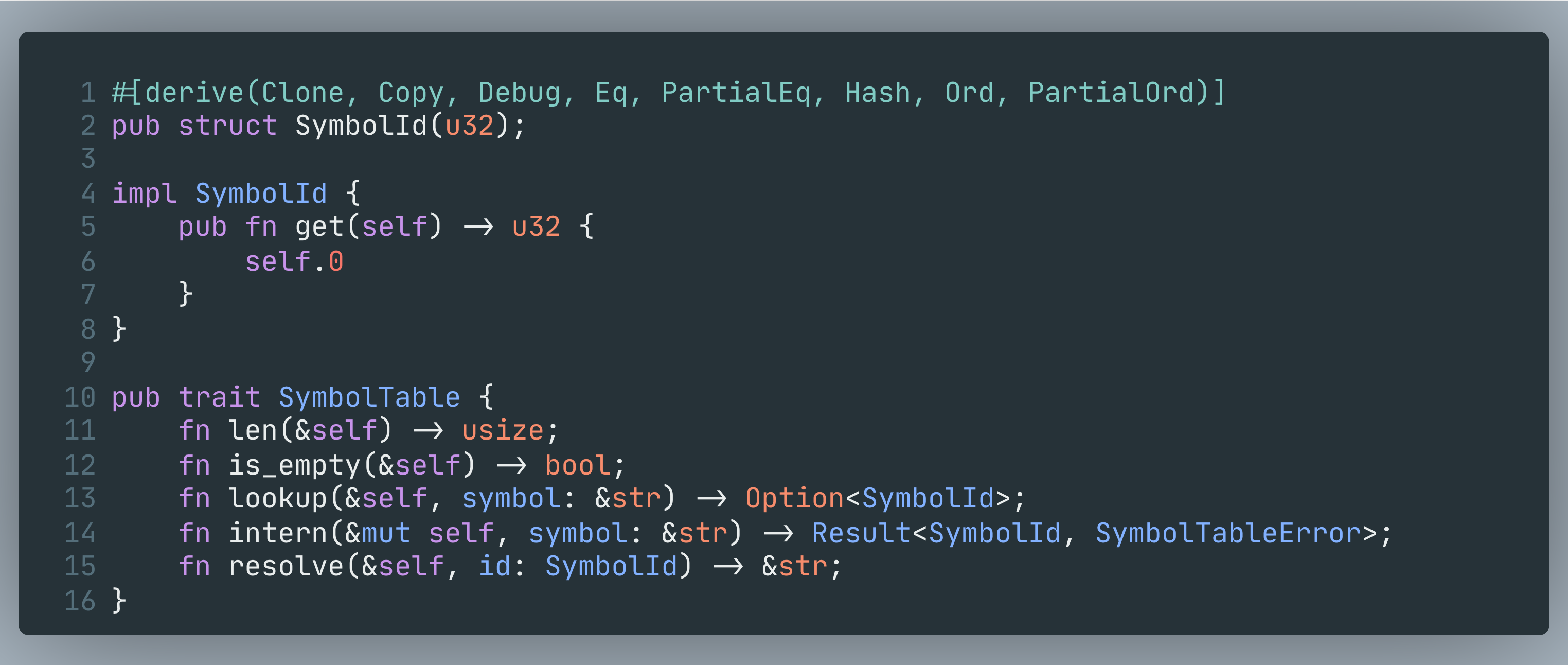
The baseline: ArcSymbolTable
The simplest correct interner in Rust is: allocate each unique string once and share it via Arc.
Chronoxide’s first implementation looked like this (simplified):

How it behaves:
On a miss,
intern()allocates a newArc<str>(heap allocation + copy), pushes it intoid_to_symbol, and inserts it intosymbol_to_id.On a hit, it returns the previously assigned ID.
Why it’s attractive:
Basic, safe, and straightforward to reason about.
resolve()is effectively&self.id_to_symbol[id](returns a pointer/len), which is extremely fast; the cost comes later when you actually process the string bytes.
The first red flag: per-symbol allocation overhead
On x86_64, both &str and Arc<str> are fat pointers (pointer + length). The handle itself is small — the real cost is that each unique Arc<str> also requires a heap allocation.
use std::{mem::size_of, sync::Arc};
assert_eq!(size_of::<&str>(), 16);
assert_eq!(size_of::<Arc<str>>(), 16);Every unique Arc<str> allocation includes:
refcount header (strong/weak, typically
2 * usize),the string bytes,
allocator metadata and size-class rounding.
With a workload dominated by short strings (~10–20 bytes), this fixed per-symbol overhead becomes painful.
What 11 million OTLP messages told me
I processed 11,376,766 real OTLP messages (time window is 3.5 hours) and collected label statistics:
Data points observed: 413,593,326
Series observed: 79,005,309
Unique symbols interned: 2,621,843
And the most important part for the SymbolTable design: typical string lengths are small:
This is the “Arc<str> pain zone”: when many strings are ~10–20 bytes, the per-string allocation/header/rounding dominates.
The real problem: allocation count and fragmentation
ArcSymbolTable does one allocation per unique string.
With ~2.62M unique symbols, that’s ~2.62M heap allocations just for symbol storage, plus additional allocations for growing the HashMap and Vec.
That hurts in two ways:
CPU cost in the hot path: allocating and copying strings for misses.
Allocator overhead: lots of small allocations scatter across allocator size classes; size-class rounding and bookkeeping add overhead beyond “useful string bytes”.
To quantify this, I measured allocation behavior (custom TrackingAllocator) and CPU (Criterion). The numbers are in the Results section below.
The fix: ArenaSymbolTable
The production data suggested the right optimization: stop allocating per string.
ArenaSymbolTable stores all string bytes in a single growing Vec<u8> (”arena”), and stores a compact location per symbol:
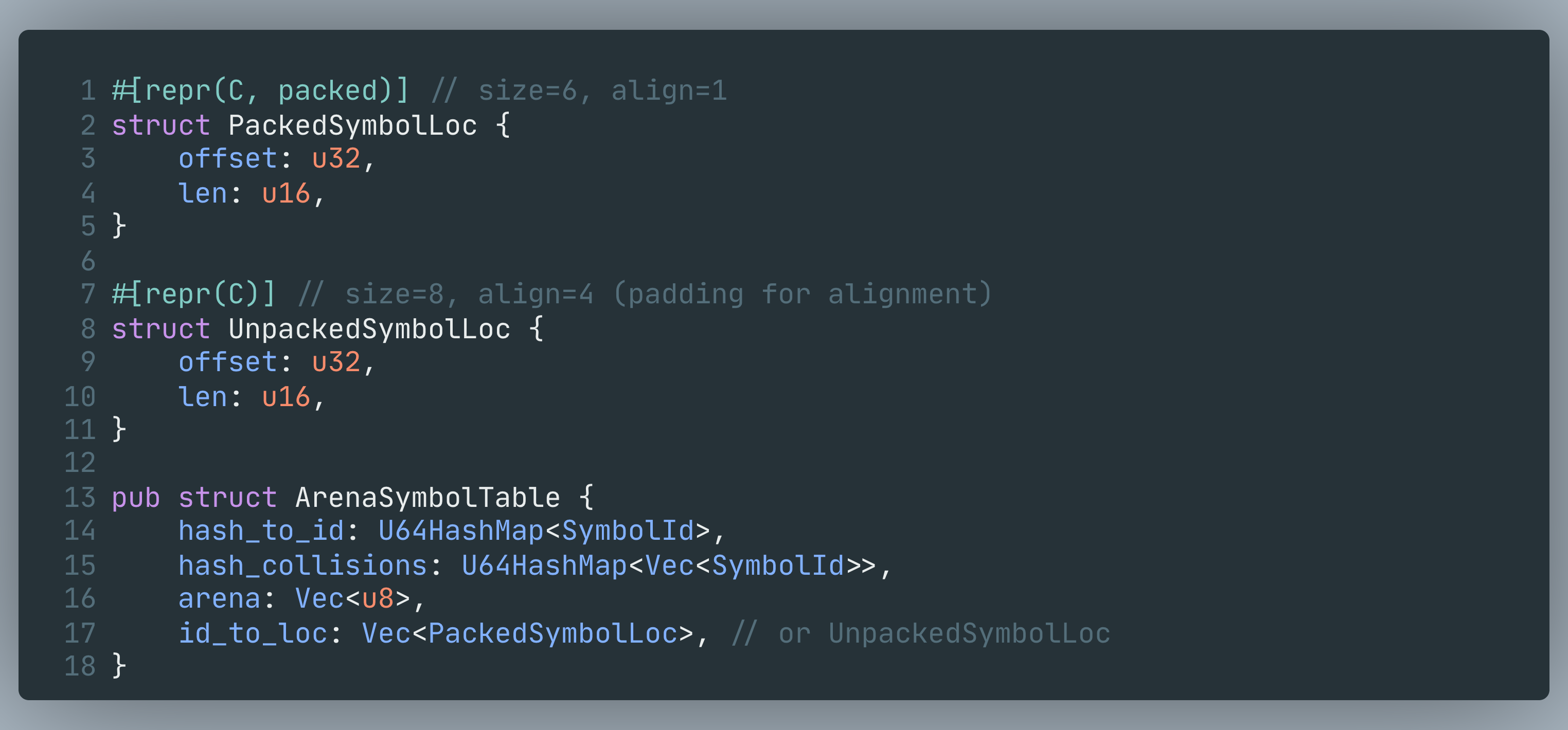
So each symbol is:
bytes appended to
arena,one
(offset,len)entry appended toid_to_loc,and an entry in
hash_to_id.
How intern() works (high-level)
Hash the input string.
Look up the hash in
hash_to_id.If the candidate resolves to the same bytes, return it.
If there’s a hash collision, scan the collision list and compare strings.
Otherwise, append bytes to
arena, appendSymbolLoc, assign nextSymbolId.
In practice, hash collisions are rare enough that the collision path is usually cold (in one production report: hash_collisions_len=0 for millions of symbols).
Why arena + (offset,len) helps so much
Almost no heap allocations: the arena grows occasionally;
id_to_locand hash tables grow occasionally.Less allocator waste: fewer small allocations → less size-class rounding / internal fragmentation.
Better CPU cache behavior:
SymbolLocis tiny; string bytes are stored contiguously.
Results: allocations and fragmentation
I can’t re-run multi-million-unique-symbol tests for every iteration, so I use a repeatable dataset shaped by production length distributions:
unique_total_symbols=100_513(all unique inserts)built from
unique_keys=512,common_values=25_000,rare_values=75_000(the example adds__name__, so keys=513)command:
cargo run --release -p chronoxide-core --example symbol_table_memory -- 512 25000 75000
The TrackingAllocator tracks requested bytes (req_current) vs allocator-reserved bytes (usable_current). internal_frag is usable_current - req_current (size-class rounding); it is not process RSS.
The time column includes TrackingAllocator’s own atomic accounting overhead; use it for rough relative comparisons, not fine-grained CPU benchmarking.
The headline is allocation count: arena stays at 18 and Lasso is nearly as low at 20, while small-string types still do tens of thousands of allocations (SmolStr: 25,873; GermanStr: 69,069), vs 100,530 for Arc<str>.
Results: speed + size
Criterion benchmark: cargo bench -p chronoxide-core --bench symbol_table -- --warm-up-time 10 --sample-size 200
Dataset: unique_total=100_513 (keys=513, common_values=25_000, rare_values=75_000).
Notes:
intern/*benches return the table to exclude drop/teardown cost from the timed region.resolve+hashhashes the resolved bytes to ensure the string is actually touched.
Best-effort size estimates after interning all unique symbols (these do not include allocator rounding / usable size). Lasso estimates are intentionally 0 because the current accounting is too far off; use TrackingAllocator results for its memory:
Evaluating Small-String Optimization (SSO)
For a deeper explanation of the “German string” layout (and why it shows up in systems code), CedarDB’s post is excellent: Why German Strings are Everywhere
Because the production stats are dominated by short strings (~10–20 bytes), I tried two “off-the-shelf” small-string-optimized crates:
german-str:
GermanStris 16 bytes and stores up to 12 bytes inline.smol_str:
SmolStris 24 bytes and stores up to 23 bytes inline (spills to heap for longer strings).
On x86_64: size_of::<german_str::GermanStr>() == 16 and size_of::<smol_str::SmolStr>() == 24.
I implemented GermanSymbolTable and SmolStrSymbolTable in the most memory-friendly way I could: store each unique string once (in a Vec<GermanStr> / Vec<SmolStr>) and index by u64 hash -> SymbolId (same collision-checked approach as the arena table) to avoid duplicating keys in a HashMap.
What I found:
SmolStris the better fit for this workload shape:intern/mixedis close to arena, and the TrackingAllocator run shows far fewer allocations thanArc<str>(25,873 vs 100,530). But it’s still much higher than arena’s ~18 allocations, and it needs more memory than arena for the same symbol set.GermanStr‘s 12-byte inline cap sits right below the typical key/value length (~13 bytes), so a large fraction spills to the heap. That shows up as more allocations (69,069) and worse allocator fragmentation in the TrackingAllocator run.
For Chronoxide’s SymbolTable goals (high cardinality, lots of unique inserts, and strict memory focus), SSO helps but doesn’t beat a purpose-built arena.
Lasso (lasso::Rodeo)
lasso is a popular interner crate built around Rodeo, which returns compact Spur keys (u32) and keeps string storage in its own arena. I added LassoSymbolTable as a drop-in comparison.
On this dataset, Lasso keeps allocations low (20 alloc_calls) and has similar requested memory to the arena tables (~6.18MiB), but its intern/mixed and intern/unique timings are slower (12.48ms and 6.43ms). Lookup/resolve are in the same ballpark as the other tables.
Memory estimates for Lasso are intentionally set to 0 because the current accounting is too far off; use the TrackingAllocator results above for realistic memory comparisons.
Packed vs Unpacked SymbolLoc
The packed vs unpacked choice is a classic “memory vs alignment” trade:
Memory: packed
SymbolLocis 6 bytes, unpacked is 8 bytes. On this dataset the packed variant reserves ~256KiB less (becauseid_to_locgrows to a power-of-two capacity). With millions of symbols this becomes multiple MiB.CPU: if you only need the returned
&str, unpacked avoids unaligned loads; if you touch/hash the bytes, theSymbolLocalignment cost is usually drowned out by the string work (and is effectively a tie here:1.4285msvs1.4262ms).Intern hot path: in this run, packed wins on
intern/uniquewhile unpacked edges out onintern/mixed, but the deltas are small enough that hashing/HashMapeffects likely dominate; don’t pick a layout solely forintern()speed.
Practical default:
If ingestion/head memory is the priority (and you rarely
resolve()), packed is a good default.If
resolve()is hot and you mostly just need the&strhandle, unpacked can be safer/faster; if you process the string bytes, packed vs unpacked is usually a wash and memory tends to dominate.
This trade-off is expected:
Arc is excellent at “read an already-interned pointer”.
Arena wins where it matters for ingestion: interning new symbols, which is heavy in high-cardinality environments.
Downsides / trade-offs of ArenaSymbolTable
No free lunch:
lookup()can be slower thanArcSymbolTablebecause it does an extraresolve()+ string equality check to protect against hash collisions (even when collisions are rare).Packed
(offset,len)metadata reduces per-symbol overhead, but it also means unaligned loads; the unpacked variant trades ~2 bytes/symbol for better alignment.Memory is monotonic (like most interners): you can’t delete individual symbols without rebuilding.
Using
u16for length means the table rejects “too long” symbols. In real TSDB systems, you typically enforce label length limits and/or truncate+hash (Grafana Cloud does this); Chronoxide follows the same direction.
Conclusion
ArcSymbolTable is a great “first correct implementation”. But after running on real OTLP workloads (11 million messages) and seeing:
~2.62M unique symbols,
most symbols in the ~10–20 byte range,
and the allocator cost of per-symbol allocations,
I moved to ArenaSymbolTable:
fewer allocations (18 vs ~100k on a 100k-symbol dataset),
lower internal fragmentation (~0.00–0.14% vs ~3.67% in the TrackingAllocator run),
and materially faster intern performance under unique-heavy workloads (≈3.85ms vs ≈8.89ms in the Criterion run).
Small-string types (SmolStr / GermanStr) were a useful sanity check: they reduce allocations and improve intern/unique vs Arc<str>, but they still can’t match an arena on allocation count or memory density for high-cardinality workloads.
The key lesson is simple: measure with real data. The workload shape (string lengths + cardinality) strongly determines whether “simple and safe” is also “fast and cheap”.
Appendix: Bench Environment
Ubuntu 25.10
Kernel
6.17.0-8-genericCPU: AMD Ryzen 9 9950X (16-core), x86_64
Build flags:
-C target-cpu=native(via.cargo/config.toml)Note: CPU frequency scaling/turbo can shift small deltas; keep clocks stable when comparing close results.