
Fast Parquet reading: From Java to Rust Columnar Readers

Imagine you have a Parquet file with well-defined schema and you want to have the fastest Parquet reader for files with that schema. In this article I'll describe my attempt. We will explore Parquet readers in Java first. Then we will explore two versions of Rust readers: naive (row-by-row) and columnar (Vectorized Columnar reader)
Parquet schema
The schema represents metrics as cumulative histogram. It contains optional string columns for labels/attributes/tags (name-value pairs) and 4 columns to model a histogram
ts - the list of timestamp
sums_double - the list of sums of all values in the histogram, if the value has type double
sums_long - the list of sums of all values in the histogram, if the value has type long
count - the list of counts of the total population of points in the histogram.
message arrow_schema {
optional binary application (STRING);
optional binary availability_zone (STRING);
optional binary build_number (STRING);
optional binary cloud_account_id (STRING);
- ...
optional group ts (LIST) {
repeated group list {
optional int64 item;
}
}
optional group sums_double (LIST) {
repeated group list {
optional double item;
}
}
optional group sums_long (LIST) {
repeated group list {
optional int64 item;
}
}
optional group count (LIST) {
repeated group list {
optional int64 item;
}
}
}The data is synthetic. First we generate JSON file with the help of the script scripts/gen_synthetic_data.py, and then convert that JSON to Parquet using js2pq

Synthetic data contains 1000 rows and has 45 columns (41 columns for labels and 4 list columns)
Java
Java implementations rely on the following libraries for Parquet reading
Apache Parquet Hadoop (parquet-hadoop v1.15.0)
Apache Arrow Parquet (arrow-dataset v18.1.0). Very fast reader because it just wraps Arrow C++ with Java API via JNI. However, it does not expose low-level API to read row groups, statistics.
Apache Parquet Avro (parquet-avro v1.15.0)
The implementation sits in the repo arrow-hadoop-parquet-readers-benchmark. The source code of readers
The only interesting part is OptimizedHadoopReader that as name implies is optimized version that uses Hadoop reader. There are two key points in the optimization:
Implements custom RecordConverter that simplifies and optimizes reading from Parquet. The simplification comes from the fact that the schema is well-defined and known upfront;
Uses fastutil as ArrayList replacement for List columns
I used jmh to write benchmarks for all the readers. The input Parquet file was copied to tmpfs to reduce IO influence on the benchmark, tmpfs is RAM file system. The benchmarks measure time to read the whole Parquet files, the result
Rust
Rust version uses arrow-rs v.54.1.0. The first version is quite straightforward
Initially I thought I would just run a benchmark, get an impressive runtime and finish the article at that. However, the runtime wasn’t that impressive, it was 13.95 ms with max used memory 158068 KBytes (Maximum RSS), just slightly faster than OptimizedReader from Java. This didn’t workout the way I expected :)

All right, we’re not going to settle at this, this is Rust, it can definitely do better.
ByteArray type for histogram
Every single read value must be wrapped by Field enum, check TripletIter, that creates that extra overhead. What if we do not write List columns separetly, but serialize them and write into single ByteArray column. This way we lose statistics that could be useful in some cases, however, we could extract them into separate column if we need, like columns min_ts, max_ts, min_value, max_value. I dediced to go with FlatBuffers as serialization library, the reasons it is:
Language agnostic
Very efficient. The writer pays the cost of serialization, readers can access the data immediately without the need of deserialization
flatc supports Rust
Histogram schema in FlatBuffers format. Note that it is similar to columnar that should give better compression (first all timestamps, them counts and so on)
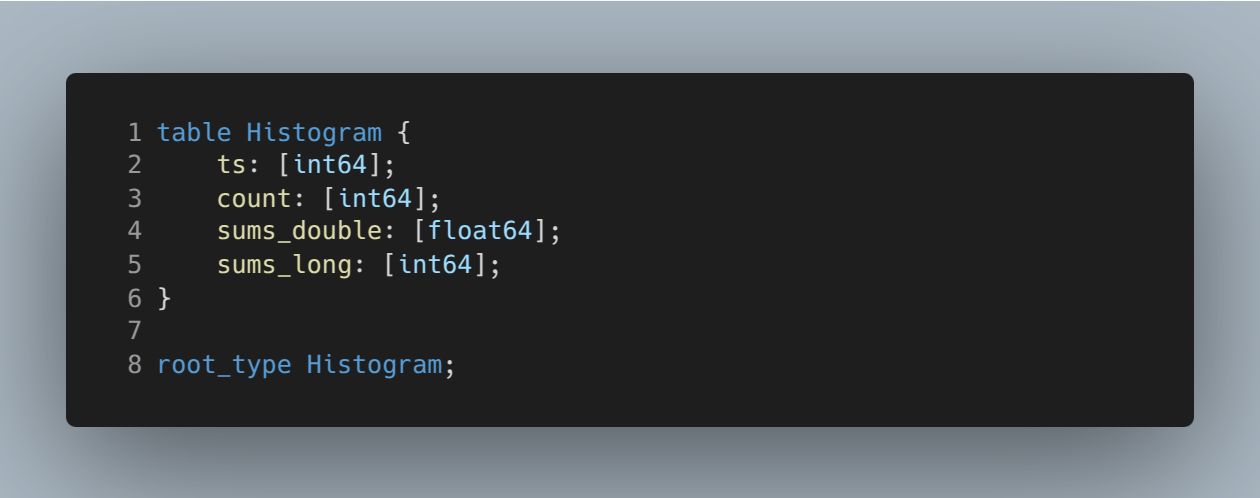
js2pq has a flag use_flatbuffers to write Parquet with ByteArray column binary_data. Let check how fast this version runs

5.87 ms with max used memory 108356 KBytes.
Interesting observation, Histograms written as a single ByteArray column are better compressed (the same ZSTD compressor with level 3) than separate List columns, it is 12.4% smaller which is counterintuitive at first, however, likely ZSTD seeing more than 1 column likely helps with better compression:
The size of syntetic.parquet is 481597 bytes
The size of syntetic_flatbuffers.parquet is 421679 bytes
Is there another way to make the reading faster?
Columnar is the way
The beautify of the initial version is its simplicity, but the price is slow runtime. The issue is the line #8
let iter = reader.into_iter();where we convert reader to RowIter. The documentation warns about that:
Parquet stores data in a columnar fashion using Dremel encoding, and is therefore highly optimised for reading data by column, not row. As a consequence applications concerned with performance should prefer the columnar arrow or ColumnReader APIs.
Internally RowIter uses ColumnarReader, the trace:
However, it has to align rows from different columns and as mentioned above, it wraps every single read value into Field enum, check TripletIter, that creates that extra overhead.
I’ve noticed there not many good articles/presentations that talk how the data is written into Parquet for nested columns (striping and assembly algorithms from the Dremel paper), my list of useful readings:
Rust Arrow Parquet project:
The understanding of the assembly algorith is required to write the reader for List type! After many unsuccessfull attempts I managed to implement the correct assembly algorith that respects repetitions and definitions for List column, check the method read_repeated_column. The runtime now is 2.85 ms with max used memory 15460 Kbytes. We got it to run 4.89 times faster and requiring 10.2 times less RAM, not bad!

All the benchmarks in a single table
Notes
Both Java and Rust benchmarks use the read data by summing it into counter.
Thanks for sharing, Art!
What's the total file size? 2.85 ms is to read the whole parquet file?