
43 Bytes per Series: How I Compressed OTLP labels with Packed KeySets

When you ingest OTLP metrics, every datapoint carries a labelset (metric name plus label pairs). The LabelSetStore is the hot path that maps a canonical labelset to a SeriesRef and deduplicates the series. The storage layout you choose here determines both memory footprint and ingestion CPU.
In the previous artilce we discussed SymbolTable
In this one we build different versions of LabelSetStore. This work is inspired by https://habr.com/ru/companies/flant/articles/878282/ (in Russian).
This article walks through three LabelSetStore implementations in Chronoxide, plus two sealed snapshots of the KeySet store for maximum density:
NaiveLabelSetStore – intentionally inefficient, uses owned strings per series.
FlatInternedLabelSetStore – interns keys/values and stores label pairs in a flat arena.
KeySetDictEncodedLabelSetStore – groups by keyset and dictionary-encodes values.
FixedWidthPackedKeySetLabelSetStore – read-only, byte-aligned packing (1/2/4 bytes per key).
BitPackedKeySetLabelSetStore – read-only, bit-packed storage for maximum compression.
TL;DR
Naive is easy to reason about, but it explodes memory and allocator pressure.
FlatInterned is faster and far more memory efficient with almost no fragmentation.
KeySetDictEncoded minimizes memory by sharing keys and dictionary-encoding values.
FixedWidthPackedKeySet and BitPackedKeySet (sealed, read-only snapshots produced at report time) win on memory: ~67/52 bytes per series (Allocated/Used) for fixed-width, and ~58/43 for bit-packed (vs ~233/210 for FlatInterned).
Baseline: NaiveLabelSetStore
The naive store keeps each labelset as its own vector of owned strings:
Vec<Vec<OwnedKeyValue>>
OwnedKeyValue { key: String, value: String }Each series allocates:
a separate
Vecheader (ptr/len/cap),per-label heap allocations for
Stringkeys and values,and hash map bookkeeping for series lookup.
This is correct but hostile to memory: millions of small allocations amplify allocator overhead and internal fragmentation.
Memory blowup in practice
On a 400k-message ingest run, RSS rises to ~35 GiB in under a minute:
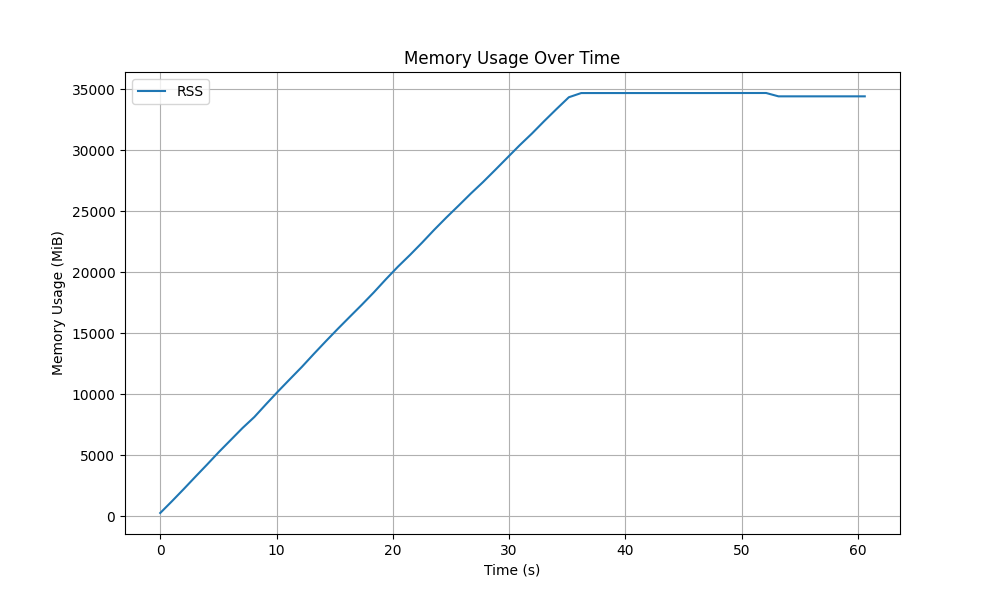
This uses the same capture as the 11M-message workload below; the chart shows the first ~400k messages.
This is not a pathological input. The naive layout stores owned strings per series, and its encode path allocates OwnedKeyValue (new String key/value) before it can even check whether the labelset already exists. That means every intern attempt allocates, even on cache hits, which amplifies allocator churn and keeps RSS high.
Criterion results
Intern unique: 15.042 ms
Visit 50k: 331.69 us
Naive allocation profile (100k series)
TrackingAllocator output:
Alloc Calls: 1,100,017
Req Current: 38,573,968B
Usable Current: 55,782,208B
Internal Fragmentation: 30.85%
Estimate Used Bytes: 37,200,128B
Why we need a better layout
Naive storage is correct but too expensive. We need to:
avoid per-series
Vecallocations,intern repeated strings instead of storing
Stringfor every series,and ideally reuse keysets to compress labelsets further.
Improved: FlatInternedLabelSetStore
FlatInternedLabelSetStore fixes the two big problems:
It interns keys and values using
SymbolTable, so repeated strings are stored once.It stores all label pairs in a single flat
Vec<InternedKeyValue>, with per-series offsets (SeriesLoc) pointing to slices inside the flat array.
This removes the per-series Vec and per-string heap allocations, and it preserves fast labelset reads by slicing the flat array.
It is a drop-in performance win without changing query semantics. See the comparison section for the numbers.
Maximum compression: KeySetDictEncodedLabelSetStore
KeySetDictEncodedLabelSetStore takes the memory optimization further by separating keys from values and dictionary-encoding values per key (global across keysets):
A keyset is a sorted list of label keys in canonical order (sorted by key string).
For each key, we keep a value dictionary (global across keysets):
SymbolId -> ValueCode.Each series row stores only
ValueCodeentries, one per key in the keyset.
This means:
keys are stored once per keyset,
values are stored once per key dictionary,
series rows are dense arrays of compact codes.
Note on normalization: the
encodepath uses normalize_label_key/normalize_label_value, which return a Cow and only allocate a truncated copy when the label exceeds limits; in-range labels are borrowed, so normalization is allocation-free in the common case (interning still allocates for new symbols).
It is highly effective when you have many series that share the same keyset and repeated values. It produces the smallest memory footprint among the mutable stores in the experiment.
To minimize memory further, this store supports two sealed read-only layouts:
FixedWidthPackedKeySetLabelSetStore stores
ValueCodeentries in byte-aligned widths (0/1/2/4 bytes), chosen per key based on the max code observed for that key in each keyset block. Rows remain directly indexable, so this is a good balance of speed and memory.BitPackedKeySetLabelSetStore stores
ValueCodeentries in a bitstream using the exact number of bits per key. This removes the last few bytes of overhead at the cost of bit-level unpacking on reads.
Both are snapshots of the mutable KeySet store (the vectors are shrunk to fit), so they are immutable and efficient for scan-heavy workloads. In a typical TSDB architecture, these sealed stores are created during Block Compaction or when flushing a completed block to disk/storage. They are not intended for the active ingestion path, but for the immutable historical blocks.
This is the game changer. On the 11M-message workload, the unpacked KeySet store uses ~118.75 bytes per series (Used). Fixed-width packing drops that to ~52.06 bytes, and bit-packing pushes it to ~43.07 bytes per series.
Visualization
To see how the “Keyset -> Dictionary -> Row” structure looks in practice, here is a dump of a small store with 3 series.
Notice how namespace and pod (which have higher cardinality) reuse values via codes 0 and 1, while __name__ is stored just once in the keyset and has a single-entry dictionary.
KeySetLabelSetStore
series=3 keysets=1 value_dicts=5 sum_per_key_cardinality=7 symbols=12
estimate_size_bytes=2300 estimate_used_bytes=1474
Symbols (first 200):
SymbolId(0) "__name__"
SymbolId(1) "pod_cpu_usage_seconds_total"
SymbolId(2) "cluster"
SymbolId(3) "prod"
SymbolId(4) "container"
SymbolId(5) "web"
SymbolId(6) "namespace"
SymbolId(7) "payments"
SymbolId(8) "pod"
SymbolId(9) "backend-123"
SymbolId(10) "backend-1231"
SymbolId(11) "payments2"
KeySets (first 200):
KeySetId(0): [SymbolId(0)="__name__", SymbolId(2)="cluster", SymbolId(4)="container", SymbolId(6)="namespace", SymbolId(8)="pod"]
Value Dictionaries (first 200):
Key SymbolId(0)="__name__": cardinality=1
ValueCode(0) -> SymbolId(1) "pod_cpu_usage_seconds_total"
...
Key SymbolId(6)="namespace": cardinality=2
ValueCode(0) -> SymbolId(7) "payments"
ValueCode(1) -> SymbolId(11) "payments2"
Key SymbolId(8)="pod": cardinality=2
ValueCode(0) -> SymbolId(9) "backend-123"
ValueCode(1) -> SymbolId(10) "backend-1231"
Rows per KeySet (first 200):
KeySetId(0): key_count=5 rows=3
row 0: "__name__"="pod_cpu_usage_seconds_total", ... "pod"="backend-123"
row 1: "__name__"="pod_cpu_usage_seconds_total", ... "pod"="backend-1231"
row 2: "__name__"="pod_cpu_usage_seconds_total", ... "pod"="backend-1231"
Series (first 200):
SeriesRef(0): KeySetId(0) row=0
SeriesRef(1): KeySetId(0) row=1
SeriesRef(2): KeySetId(0) row=2The tradeoff is CPU on reads. To reconstruct a labelset from a SeriesRef, the store must:
Fetch the Keyset: Resolve
KeySetIdto the list ofSymbolIdkeys.Fetch the Row: Retrieve the
ValueCodeentries for this series.Per-label resolve: For each key, hash lookup the per-key dictionary, map
ValueCode -> SymbolId, and resolve both key and valueSymbolIds back to strings via the SymbolTable.
This multi-step path (per-key hash lookup + dictionary indirection + two symbol resolves) explains why visit_labelset is ~8x slower than FlatInterned in the benchmarks (2081us vs 262us). The packed variants add further overhead due to unpacking on reads.
FlatInternedwalks one contiguous(key,value)array and performs two symbol resolves per label, which plays nicely with the hardware prefetcher.KeySetstill scans contiguous keyset + row arrays, but it adds a per-label HashMap lookup (value_dicts.get(&key)) plus an extra dictionary indirection before the same two symbol resolves.That per-label hash lookup + extra indirection is the main cache-miss risk and explains the read slowdown, especially when traversing many random series. The packed variants add further overhead (~6-17%) due to the byte- or bit-level unpacking instructions required on the read path.
Benchmarking and allocator analysis
Criterion results
The PackedKeySet visit time (2211.4 us) is ~7% slower than the unpacked version (2073.4 us). This delta represents the pure CPU cost of bit-unpacking the values. However, both KeySet variants are significantly slower than FlatInterned (~258 us) due to the dictionary lookups. This confirms that while bit-packing adds a small CPU tax, the primary latency cost comes from the dictionary structure itself.
PackedKeySet numbers come from sealing the KeySet store at report time. This is a read-only snapshot, not an ingestion-time layout.
Allocation and fragmentation (100k series)
TrackingAllocator output:
Results on 11 million OTLP messages
Workload summary
These results are from 11,376,766 OTLP messages captured over a 00h:54m window and replayed from /tmp (RAM-backed) to minimize storage I/O:
Sum per-key cardinality is the sum of per-key dictionary sizes across all keys (values counted once per key). Global distinct values is the number of unique values across all keys.
RSS comparison across stores
RSS over time for FlatInterned and KeySetDictEncoded stores (same workload, same host):
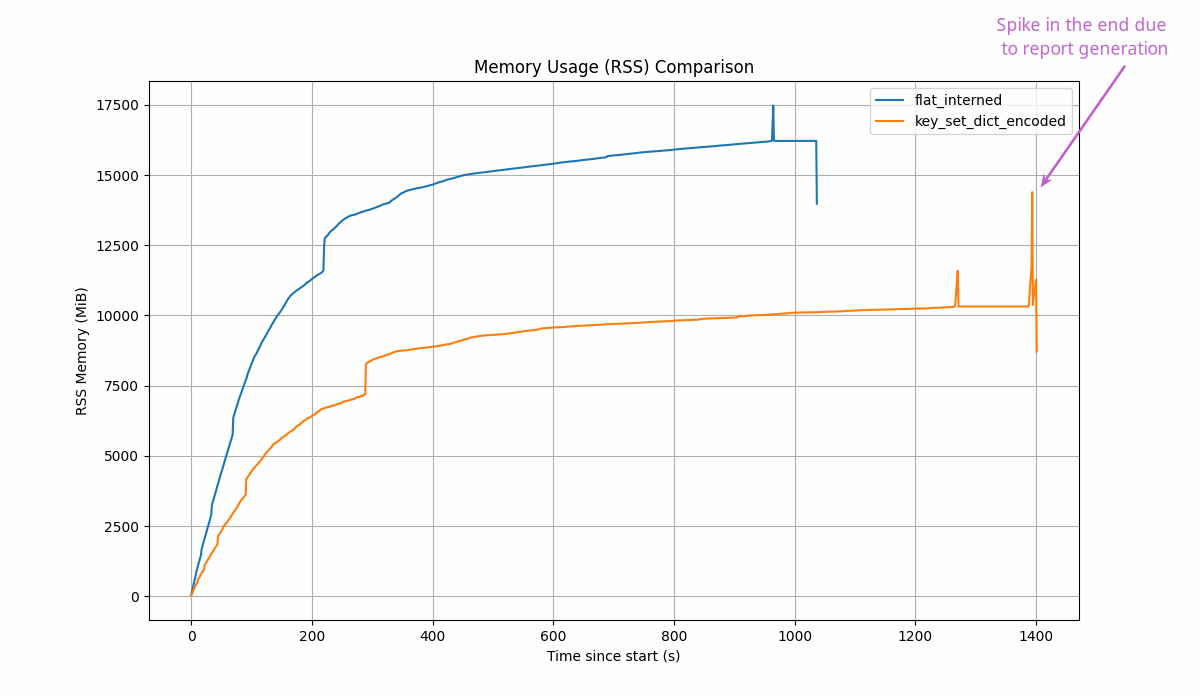
Latency on real workload
DP Intern is a per-message average time per datapoint spent in labelset interning.
/usr/bin/time -pv
End-of-run stats from /usr/bin/time -pv (pinned to CPU cores 10-16):
Store statistics
Store size from the Markdown reports:
These statistics confirm that dictionary encoding and packing deliver massive memory savings on real-world datasets.
BitPackedKeySet is the clear winner for density, requiring only ~58 bytes per series (Allocated) or ~43 bytes per series (Used), which is a ~4x reduction compared to FlatInternedLabelSetStore (~233/210 bytes).
FixedWidth already gets you to ~67/52 bytes per series, while the unpacked KeySetDictEncoded layout lands at ~176/119 bytes.
Comparison at a Glance
Rust implementation notes
Normalization uses
Cowto avoid allocation on in-range labels; only truncation allocates.Keysets are stored as
Arc<[SymbolId]>for deduplication and cheap clones between tables and snapshots.The core layouts use flat
Vecarenas plus compactu32ids/codes (SeriesRef,SymbolId,ValueCode) to reduce footprint.Sealed snapshots call
shrink_to_fitto drop unused capacity before measuring/packing.U64HashMapuses a customU64IdentityHasher(no-op hasher) to avoid double-hashing, as the store pre-hashes labelsets.Memory estimation logic (
estimate_hashmap_table_bytes) is aware ofhashbrown/ SwissTable control bytes to accurately account for overhead.
Summary
If you need a safe baseline, NaiveLabelSetStore is simple but too expensive for real workloads.
If you want a default that is fast and memory efficient, FlatInternedLabelSetStore is the best balanced choice.
If you are chasing the lowest memory possible and can tolerate slower labelset reads, KeySetDictEncodedLabelSetStore wins on memory by a large margin.
In practice:
Use FlatInterned for ingestion + query hot paths.
Use KeySetDictEncoded for memory-constrained scenarios or background compaction paths.
Seal to FixedWidthPacked or BitPacked when you want a read-only snapshot with maximum density.
Appendix
Bench Environment
Ubuntu 25.10
Kernel
6.17.0-8-genericCPU: AMD Ryzen 9 9950X (16-core), x86_64
Build flags:
-C target-cpu=native(via.cargo/config.toml)Note: CPU frequency scaling/turbo can shift small deltas; keep clocks stable when comparing close results.
{kind=link}
{kind=link}